“As powerful as I believe quantitative analysis and survey research can be, I can’t help but feel that part of the problem is that many of us as social scientists have lost track of what politics means for many people (…) We know a lot about what people do, but very little about what it means for them.”
Rasmus Kleis Nielsen, 2016
“Donald Trump tiene las mismas chances de ganar que las que tenía el Brexit” escuché decir ayer y bastó para encender la alarma.
No es la primera vez que las encuestas erran con sus predicciones y sus proyecciones de intención de voto. Tanto en el plebiscito por la paz en Colombia como en el “Brexit” las consultoras tuvieron malas perfomances.
¿Por qué se reportan decenas y decenas de encuestas que aseguran que va a ganar un candidato A cuando luego resulta que la victoria es para el B? ¿Hay intencionalidad política? ¿Hay que dejar de hacerlas?
Encuestas y representatividad
Existe un solo momento en el que todas las personas dan su opinión al respecto de una contienda política y es el mismísimo día de la elección. Solo en ese momento la muestra es “completa”. Cualquier consultora o encuestadora se va a basar, entonces, en una sub-muestra, y esto ya implicará un desafío, dado que se intentará utilizar a ese sub conjunto para decir lo que va a suceder con el total.
Para que los resultados de la encuesta sean representativos o buenos predictores uno de los mejores aliados que se puede buscar es el de la aleatoriedad: si deseamos saber cuál es la intención de voto en Florida para Hillary Clinton lo ideal sería tomar al azar distintas personas y consultarles su opinión. Con un número considerable podremos comenzar a tener una estimación que no va a estar (o tal vez sí, Donald) tan lejos de lo que efectivamente sucederá.
Aun así, es importante también considerar el medio por el cual se hace la encuesta. Cuando las líneas telefónicas no estaban lo suficientemente expandidas a lo largo de la población y el bien era un lujo al que accedía un determinado sector económico y social, si el relevamiento de datos se hacía por esta vía, por más que uno eligiera al azar a qué número llamar y cuál no los datos que se obtendrían no serían para nada representativos.
Notemos que aún con un método de aleatoriedad la encuesta estaría sesgada, es decir, esta última es una condición necesaria pero no suficiente.
El problema no es tan sencillo de solucionar: supongamos que para evitar este tipo de inconvenientes decidimos salir a caminar por la ciudad para consultar la intención de voto.
Aunque recorramos todo el territorio a pie seleccionando a hombres y mujeres al azar para poder realizar nuestra predicción existen personas que responden y otras que deciden no hablar. Allí puede haber otro sesgo. Si las personas que tienden a responder son más proclives a votar al candidato con menos probabilidades (por eso desearían, tal vez, inflar las encuestas) entonces estaríamos sobre-estimando la intencionalidad de voto para ese/a político/a.
En los días previos a las elecciones estadounidenses, algunos analistas afirmaban que, como no se había tenido en cuenta adecuadamente a la población de latinos en Florida, la intencionalidad de voto para Hillary Clinton estaba subestimada. Con el diario del lunes sabemos que no fue así, sino todo lo contrario, pero es importante el ejemplo para resaltar la relevancia de la representatividad.
En los análisis del día de la fecha también se encuentran muchas hipótesis que explican el triunfo de Trump por haberse subestimado la participación electoral de hombres y mujeres blancxs sin estudios universitarios (colectivo que, en general, adhiere al candidato republicano)
Y por si fuera poco, existe otro potencial inconveniente: las personas cambian de opinión constantemente y pueden responder distintas cosas de una encuesta a otra o, por cuestiones de presión social o preferencias por no revelar el voto; incluso pueden llegar a mentir.
Hasta aquí ya queda claro que los reportes estadísticos de una encuesta pueden estar sujetos a problemas de sesgo, tanto por cuestiones elementales de diseño como por eventos imperceptibles.
La letra chica: el intervalo de confianza.
Supongamos que deseamos saber qué porcentaje de la población va a optar por el candidato A, por lo que se realiza un relevamiento muestral, se procesan los datos y se presenta un porcentaje, digamos un 30%.
Sin embargo, ya sabemos que esa estimación se basa sobre los resultados que se desprendieron de una muestra que lejos está de ser el total de la población. Tendremos un parámetro desconocido (verdadera intención de voto A) que se lo estimará partir de una muestra; naturalmente, existirá un margen de error (la estimación no es exacta, reporta el promedio).
El intervalo de confianza constituye un rango de valores para los cuales se estima que caerá el verdadero valor. Por lo general, se estiman “intervalos de confianza al 95%”, lo que significa que para la muestra obtenida se estima que el verdadero valor del parámetro caerá dentro del rango presentado en el 95 por ciento de los casos.
Cuando se agranda el tamaño de la población se puede precisar el rango del intervalo pero, y esto es fundamental, nunca nos vamos a poder desprender de él, a menos que encuestemos a absolutamente todas las personas que efectivamente vayan a votar, pero eso se llama “día de la votación” y pasó ayer.
Por otra parte, si extendemos el rango de valores para los cuáles decimos que va a estar el porcentaje de votos entonces es muy probable que luego acertemos, pero a costa de dar muy poca información. Si afirmo que Hillary va a sacar entre 40 y 60 por ciento de los votos, es casi seguro que voy a estar en lo cierto, ¿pero qué información útil podemos derivar de esa afirmación?
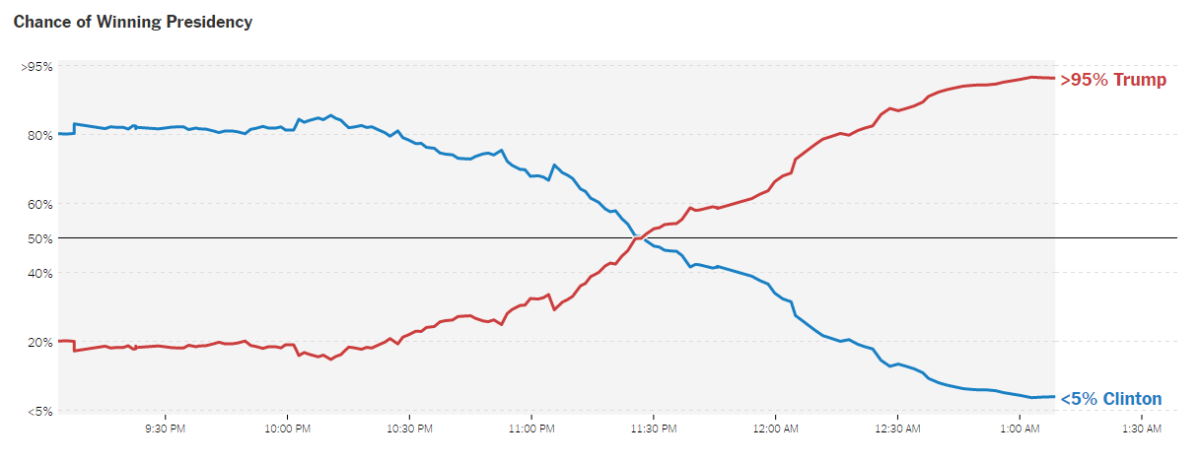
Probabilidad de ganar no es igual a intención de voto
Una de las mayores confusiones que se podían generar a partir de los datos de las encuestadoras era la de entender por “probabilidad de ganar” a “intención de voto”. Como relata la nota del día de hoy de Clarín (ver referencias), el diario The New York Times afirmaba que Clinton tenía un 85 por ciento de posibilidades de ganar la elección. Esto no implica que Clinton, según las encuestas, tenía un 85% de intención de voto.
Por el contrario, lo que ese número afirmaba era que, cuando se realizaron simulaciones de las elecciones con los datos recolectados por intención de voto, el resultado global era que, si se hacía la repetición 1000 veces, Clinton resultaba ganadora en 850 simulaciones.
Comentarios finales
Si hay algo de lo que ya no tenemos dudas es que los métodos estadísticos pueden no ser acertados.
Los datos nos resumen infinidad de relaciones, nos indican muchas veces el sendero hacia el cual debemos dirigir una política pública o nos describen situaciones que, de no ser por ellos, no podríamos conocer. Pueden también contarnos acerca de conductas, comportamientos y acciones que tienen los individuos. No obstante, en una votación pareciera ser que hay algo más que un número: hay una persona, que en un contexto dado, conmovido y atravesado por cuestiones que no se pueden predecir con un algoritmo, eligen a quién poner en un sobre para determinar el futuro de un país. Ese día el número no predice a la acción, es la acción la que determina el número.
Referencias
http://www.clarin.com/mundo/encuestas-equivocaron-Trump_0_1684031664.html